Assignment 2: Find drugs for cancers that target genes related to cell proliferation
During this assignment, we will investigate another example SPARQL query of Wikidata, called “Find drugs for cancers that target genes related to cell proliferation”. We will first go through the basics of a SPARQL query. Second, we will find out how to execute the query and retain or share results. Last, we will expand the query and make other (small) changes, to understand the structure of a SPARQL query better, and see what other data is available in Wikidata.
Step by Step
We will use the following example, which makes use of Gene Ontology terms in Wikidata and drug information. There are lots of comments written before the actual query starts (which we will ignore for now).
New building blocks
The complete query is depicted below, and has one new building block, called LIMIT (last line of query). This is a so-called solution modifier, which limits the number of rows returned from a query. In the example below, we will receive a maximum of 1000 rows as a result.
LIMIT
SELECT ?drugLabel ?geneLabel ?diseaseLabel #?biological_processLabel
WHERE {
?drug wdt:P129 ?gene_product . # drug interacts with a gene_product
?gene wdt:P688 ?gene_product . # gene_product (usually a protein) is a product of a gene (a region of DNA)
?disease wdt:P2293 ?gene . # genetic association between disease and gene
?disease wdt:P279* wd:Q12078 . # limit to cancers wd:Q12078 (the * operator runs up a transitive relation..)
?gene_product wdt:P682 ?biological_process . #add information about the GO biological processes that the gene is related to
?biological_process (wdt:P361|wdt:P279)* wd:Q189101 . # chain down subclass/part-of
#Change the last statement (wd:Q189101) to limit to genes related to certain biological processes (and their sub-processes):
#cell proliferation wd:Q189101 (Current example)
#apoptosis wd:Q14599311
#uncomment the next line to find a subset of the known true positives (there are not a lot of them in here yet; will lead to 4 drugs if biological process is cell proliferation 2018-12-17)
#?disease wdt:P2176 ?drug . # disease is treated by a drug
SERVICE wikibase:label {bd:serviceParam wikibase:language "en" . }
}
LIMIT 1000
There are other solution modifiers available, such as ORDER BY, which can be used to sort the query solutions on the value of one or more variables. Adding ORDER BY ?diseaseLabel above the LIMIT line, will sort our results based on the name of the diseases we are retrieving from this query.
SELECT DISTINCT
- Run the query above in the SPARQL endpoint, and look up how many results you have.
- Change the result clause to the line depicted below, and look at the amount of results:
SELECT DISTINCT ?drugLabel ?geneLabel ?biological_processLabel ?diseaseLabel
The DISTINCT modifier removes duplicate rows from the query results.
(Un)Comment
- Comments (depicted with a hash ‘#’) can help explaining the query (not only to others, but also to yourself).
- Within comments, one can also add additional query options, which has been done in the following lines:
#uncomment the next line to find a subset of the known true positives (there are not a lot of them in here yet; will lead to 4 drugs if biological process is cell proliferation 2018-12-17)
#?disease wdt:P2176 ?drug . # disease is treated by a drug
You can uncomment by removing the ‘#’ sign, and run the query again.
Additional visualisations
- Comment the line related to true positives again (from the assignment above).
- Change the view from ‘Table’ to ‘Scatter chart’:
The following graph should now appear (click on on of the coloured circles in the graph, to obtain the diseaseLabel):
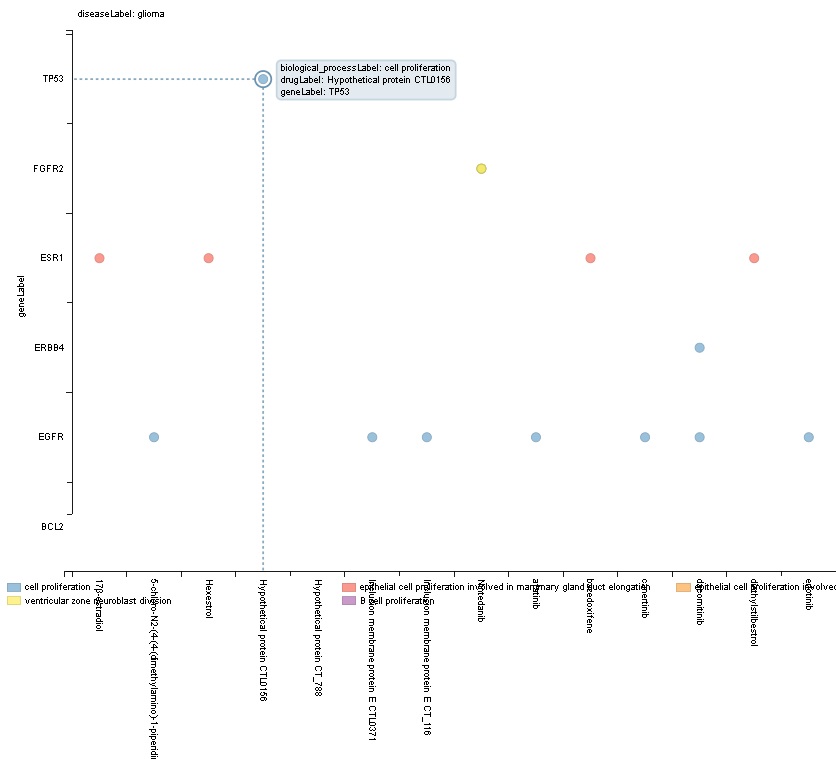
Question 1A: Which variables are depicted in which manner?
Question 1B: What would change to the visualisation, if you switch the place of the variables ?geneLabel and ?biological_processLabel with one another?
(Answers can be found here).
Changing the Question
In the previous exercises, we were making (small) adjustments, to understand the structure of a SPARQL query (better). Now, we will focus on adapting the query to answer aditional questions.
?biological_process
Suppose you are interested in not only “cell proliferation” as a GO- term, but you would also want to include genes that are related to ‘apoptosis’ (wd:Q14599311) and ‘cell death’ (wd:Q2383867). Change the example query to obtain the required results.
(Answers can be found here).
?drug structure
Suppose you want to obtain the chemical structure of the drugs involved as an InChIKey, if these are available in Wikidata. Change the example query to obtain the required results.
(Answers can be found here).
?References
Since there are only 4 known true positives (see the (Un)Comment section), you want to find out if there are any papers describing these drugs. The results should be ordered based on drugname, and we want to see the article names. Change the example query to obtain the required results.
(Answers can be found here).
?MORE biology
You can probably think of some other questions you would like to ask to Wikidata. Try to come up with a expansion of the query we are working on now, or find another example on Wikidata you want to understand and expand (ask your instructors for help if needed).